SGDClassifier
import pandas as pd
fish = pd.read_csv('https://bit.ly/fish_csv_data')
Species 열을 제외한 나머지 5개는 입력 데이터로, Species 열은 타깃 데이터로 사용한다.
fish_input = fish[['Weight', 'Length', 'Diagonal','Height','Width']].to_numpy()
fish_target = fish['Species'].to_numpy()
훈련 세트와 테스트 세트로 나눈다.
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(fish_input, fish_target, random_state = 42)
훈련 세트와 테스트 세트의 특성을 표준화 전처리한다.
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)
사이킷런에서 제공하는 확률적 경사 하강법 알고리즘 SGDClassifier을 사용한다.
SGDClassifier의 객체를 생성할 때 두 개의 매개변수를 지정한다.
loss는 손실 함수의 종류를 지정하는 것이며 'log'로 지정하여 로지스틱 손실 함수를 사용할 수 있다.
max_iter는 수행할 에포크 횟수를 지정하는 것이다.
from sklearn.linear_model import SGDClassifier
sc = SGDClassifier(loss = 'log', max_iter = 10, random_state = 42)
sc.fit(train_scaled, train_target)
print(sc.score(train_scaled, train_target))
print(sc.score(test_scaled, test_target))
결과값에 ConvergenceWarning 경고는 max_iter 매개변수의 값이 충분하지 않음을 의미한다.
모델을 이어서 훈련할 때는 partial_fit()메서드를 활용한다.
이 메서드는 fit()메서드와 사용법이 같지만 호출할 때마다 1에포크씩 이어서 훈련한다.
sc.partial_fit(train_scaled, train_target)
print(sc.score(train_scaled, train_target))
print(sc.score(test_scaled, test_target))
에포크와 과대/과소적합
훈련 세트에 있는 전체 클래스의 레이블을 partial_fit()메서드에 전달해주기 위해 np.unique()함수로 train_target에 있는 7개의 생선 목록을 생성한다.
에포크마다 훈련 세트와 테스트 세트에 대한 점수를 기록하기 위해 2개의 리스트를 생성한다.
import numpy as np
sc = SGDClassifier(loss = 'log', random_state = 42)
train_score = []
test_score = []
classes = np.unique(train_target)
300번의 에포크 동안 훈련을 반복하고 반복마다 리스트에 점수를 추가한다.
for _ in range(0, 300):
sc.partial_fit(train_scaled, train_target, classes = classes)
train_score.append(sc.score(train_scaled, train_target))
test_score.append(sc.score(test_scaled, test_target))
300번의 에포크 동안 기록한 훈련 세트와 테스트 세트의 점수를 그래프로 그린다.
import matplotlib.pyplot as plt
plt.plot(train_score)
plt.plot(test_score)
plt.xlabel('epoch'); plt.ylabel('accuracy'); plt.show()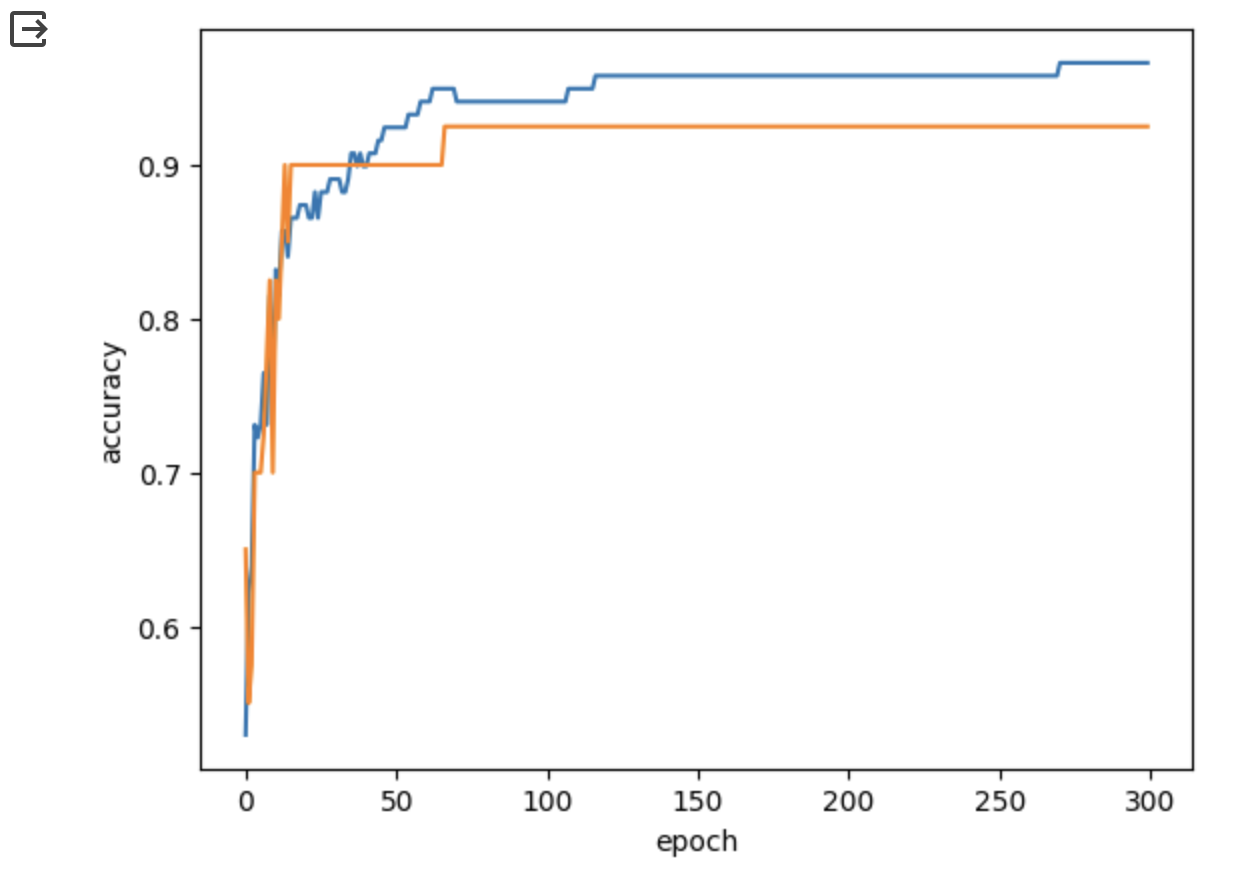
위 결과 그래프를 통해 백 번째 에포크 이후 두 세트의 점수가 벌어지는 것을 확인할 수 있다.
백 번째 에포크가 가장 적절한 반복 횟수로 확인되었기 때문에 반복 횟수를 100으로 맞추고 모델을 다시 훈련시킨다.
SGDClassifier는 일정 에포크동안 성능이 향상되지 않으면 더 훈련하지 않고 자동으로 멈춘다. 이를 방지하고자 tol 매개변수에 None으로 지정하여 max_iter만큼 무조건 반복하도록 설정한다.
sc = SGDClassifier(loss = 'log', max_iter = 100, tol= None, random_state=42)
sc.fit(train_scaled, train_target)
print(sc.score(train_scaled, train_target))
print(sc.score(test_scaled, test_target))
SGDClassifier의 loss 매개변수의 기본값은 'hinge'이다. 힌지 손실은 서포트 벡터 머신이라 불리는 또 다른 머신러닝 알고리즘을 위한 손실함수이다.
힌지 손실을 사용해 같은 반복 횟수 동안 모델을 훈련하는 코드는 아래와 같다.
sc = SGDClassifier(loss = 'hinge', max_iter = 100, tol= None, random_state=42)
sc.fit(train_scaled, train_target)
print(sc.score(train_scaled, train_target))
print(sc.score(test_scaled, test_target))
'AI > 혼자공부하는머신러닝딥러닝' 카테고리의 다른 글
| [ML] 05-2 교차 검증과 그리드 서치 (1) | 2024.01.22 |
|---|---|
| [ML] 05-1 결정 트리 (1) | 2024.01.22 |
| [ML] 04-1 로지스틱 회귀 (1) | 2024.01.21 |
| [ML] 03-3 특성 공학과 규제 (0) | 2024.01.20 |
| [ML] 03-2 선형 회귀 (0) | 2024.01.20 |